
I work at Xiaomi  as a senior AI researcher. Previously, I was working at ByteDance
as a senior AI researcher. Previously, I was working at ByteDance  focusing on LLM and MLLM in Shanghai, China.
focusing on LLM and MLLM in Shanghai, China.
I am now working on multimodal large language model, reinforcement learning, LLM-related foundational research, particular in VLM, VLA and World Model. If you are seeking any form of academic cooperation, please feel free to email me at lujinghui@xiaomi.com. We are hiring interns!
I graduated with a Bachelor’s degree in Software Engineering from Xiamen University (厦门大学) and earned a Master’s degree from the School of Computer Science at University College Dublin (都柏林大学), where I was advised by Prof. Mark Keane, focusing on natural language processing. Then, I completed my PhD at University College Dublin under the supervision of Prof. Brian Mac Namee, focusing on interdisciplinary methods for Deep Learning, NLP and Human-in-the-loop. I also collaborate with Dr. Irene Li from Li Lab, the University of Tokyo closely.
My research interest includes VLA, World Model, NLP, multi-modality, document AI and human-in-the-loop. I have published 30+ papers 
🔥 News
- 2026.05: 🎉 We released OneVL, the first latent CoT method to surpass explicit CoT in autonomous driving trajectory planning while matching answer-only inference latency, via a unified VLA and World Model framework with dual auxiliary decoders for both dense supervision and interpretable vision-language explanations (1# paper of the day in Huggingface trending). | Project |
|
.
- 2026.05: 🎉 One paper has been accepted to ICML 2026 spotlight (top 2.2%).
- 2026.04: 🎉 Two papers haven been accepted to ACL 2026.
- 2025.11: 🎉 We released MiMo-Embodied, the first open-source cross-embodied foundation model that unifies autonomous driving and embodied AI, achieving SOTA on 17 embodied AI and 12 autonomous driving benchmarks. | Project |
|
- 2025.09: 🎉 One first-author paper has been accepted to AAAI 2026.
- 2025.08: 🎉 I joined Xiaomi as a Senior AI researcher in Shanghai.
- 2025.08: 🎉 Two papers haven been accepted to EMNLP 2025.
- 2025.07: 🎉 One paper has been accepted to ICCV 2025.
- 2025.05: 🎉 We released Dolphin, which is a novel multimodal document image parsing model following an analyze-then-parse paradigm. | Project |
|
- 2025.05: 🎉 Four papers have been accepted to ACL 2025.
- 2025.05: 🎉 We released WildDoc, which is the first inaugural benchmark designed specifically for assessing document understanding in natural environments. | Project |
|
- 2025.03: 🎉 We released Visual as LORA (VORA), which challenges conventional encoder-based MLLM architecture such as Llava series. | Project |
|
- 2024.10: 🎉 One first-author paper has been accepted to NeurIPS 2024.
- 2024.07: 🎉 We released LayTextLLM, interleaving layout and text information for LLM, achieving SOTA performance across multiple document AI benchmarks | Project |
|
- 2024.05: 🎉 We released MTVQA, which is the first text-centric multilingual multimodality benchmark for LLMs | Project |
|
.
- 2024.05: 🎉 One paper has been accepted to ACL 2024.
- 2024.03: 🎉 One paper has been accepted to NAACL 2024.
- 2024.02: 🎉 One co-first author paper has been accepted to COLING-LREC 2024.
- 2023.08: 🎉 I joined ByteDance as a AI researcher in Shanghai.
- 2023.06: 🎉 One first-author paper has been accepted to AAAI 2023.
- 2023.05: 🎉 One first-author paper has been accepted to ACL 2023.
- 2023.05: 🎉 One paper has been accepted to ACL 2023.
- 2022.03: 🎉 One first-author paper has been accepted to ACL 2022.
- 2022.01: 🎉I joined SenseTime Group Ltd. as a AI researcher for NLP!
- 2021.07: 🎉 One first-author paper has been accepted to ICML 2021 Workshop.
📝 Selected Publications
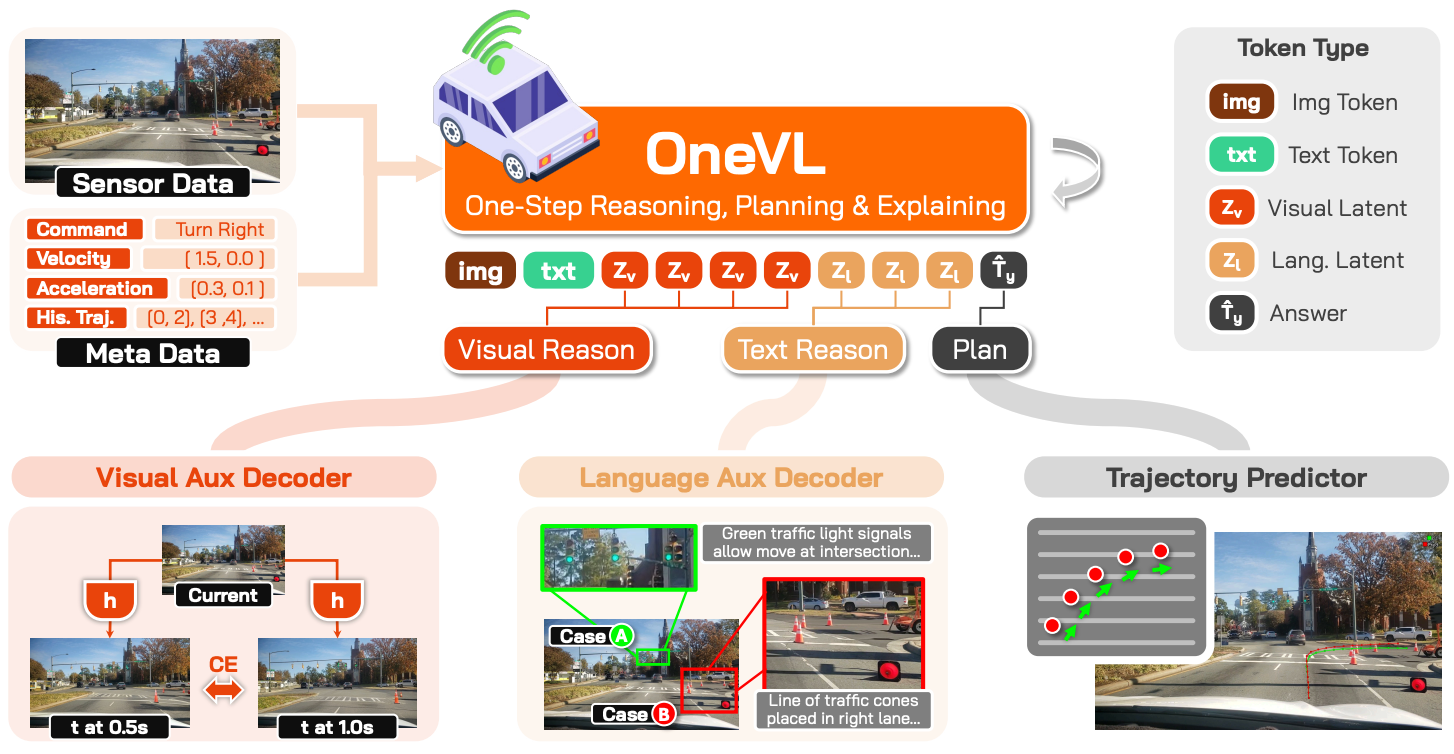
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Jinghui Lu, Jiayi Guan, Zhijian Huang, Jinlong Li, Guang Li, Lingdong Kong, Yingyan Li, Han Wang, Shaoqing Xu, Yuechen Luo, Fang Li, Chenxu Dang, Junli Wang, Tao Xu, Jing Wu, Jianhua Wu, Xiaoshuai Hao, Wen Zhang, Tianyi Jiang, Lingfeng Zhang, Lei Zhou, Yingbo Tang, Jie Wang, Yinfeng Gao, Xizhou Bu, Haochen Tian, Yihang Qiu, Feiyang Jia, Lin Liu, Yigu Ge, Hanbing Li, Yuannan Shen, Jianwei Cui, Hongwei Xie, Bing Wang, Haiyang Sun, Jingwei Zhao, Jiahui Huang, Pei Liu, Zeyu Zhu, Yuncheng Jiang, Zibin Guo, Chuhong Gong, Hanchao Leng, Kun Ma, Naiyan Wang, Guang Chen, Kuiyuan Yang, Hangjun Ye, Long Chen ✉️
Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLAbased autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. In inference, the auxiliary decoders are discarded, and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering superior accuracy at answer-only latency. These results show that with world model supervision, latent CoT produces more generalizable representations than verbose token-by-token reasoning.
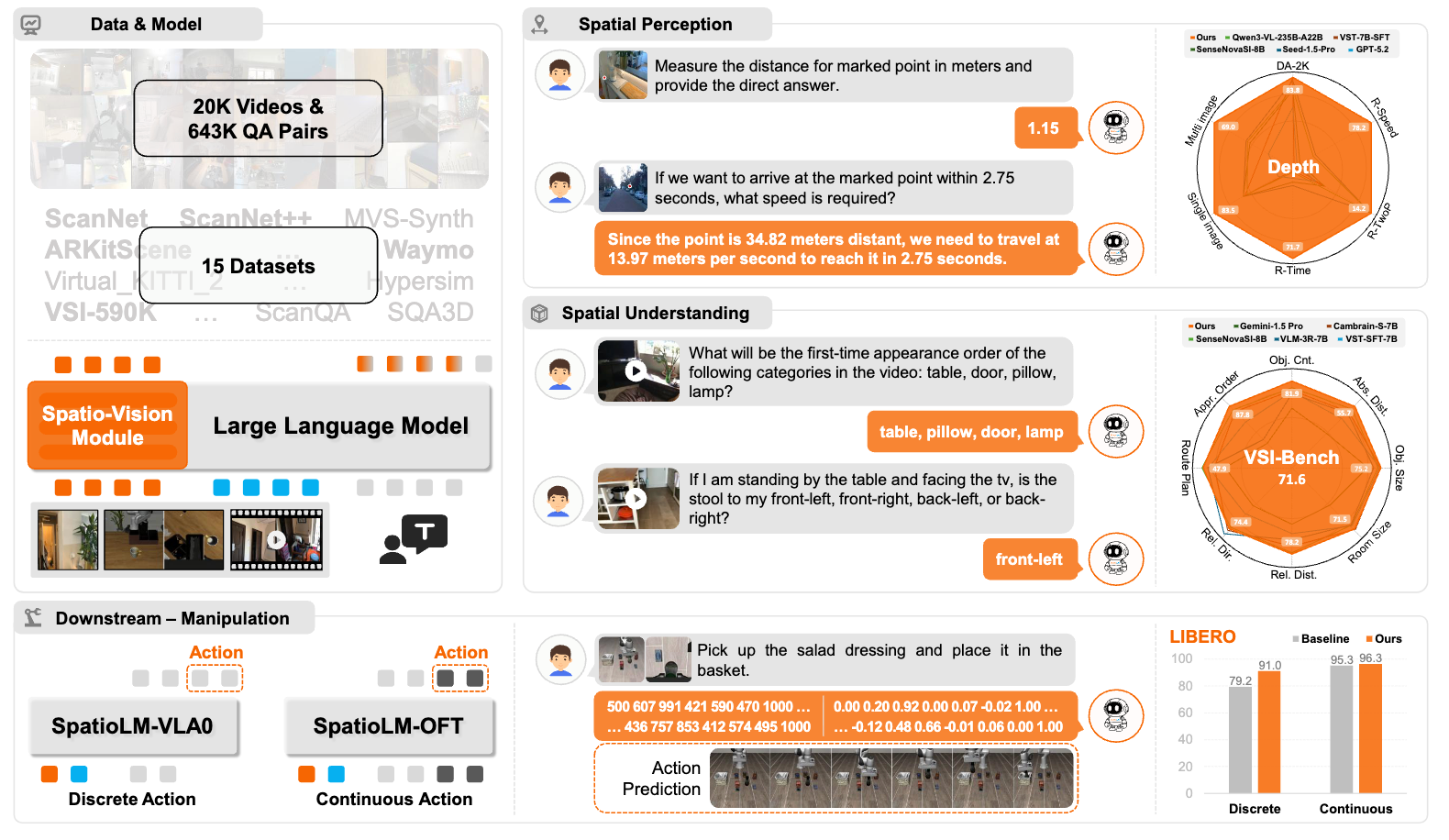
SpatioLM: Towards General Physical Spatial Intelligence in Vision-Language Models
Jing wu, Jianhua Wu, Jiayi Guan, Jiahong Chen, Jinghui Lu, Hangjun Ye, Bingzhao Gao, Long Chen ✉️
Vision-Language Models (VLMs) perform well on commonsense reasoning tasks but struggle with visual spatial reasoning. Most existing solutions introduce extra 3D priors or external spatial encoders, which increase complexity and degrade the underlying VLMs’ general-purpose capabilities after spatial fine-tuning. To this end, we propose a parameter-efficient Spatio-vision Language Models (SpatioLM), that enhances spatial intelligence without extra 3D priors or third-party spatial encoders. Concretely, we design a plug-and-play and non-invasive spatio-vision module that elicits the spatial knowledge inherent in VLMs. Furthermore, we innovatively leverage pseudo depth and camera information as supervision to guide the model in learning physically coherent representations. Extensive experiments show that SpatioLM achieves significant improvements in diverse tasks, including spatial perception and understanding while maintains the general-purpose capabilities. Notably, the model achieves an impressive score of 71.6 on the VSI-Bench (the first model to surpass 70). In addition, it attains competitive performance when transferred to embodied manipulation tasks.
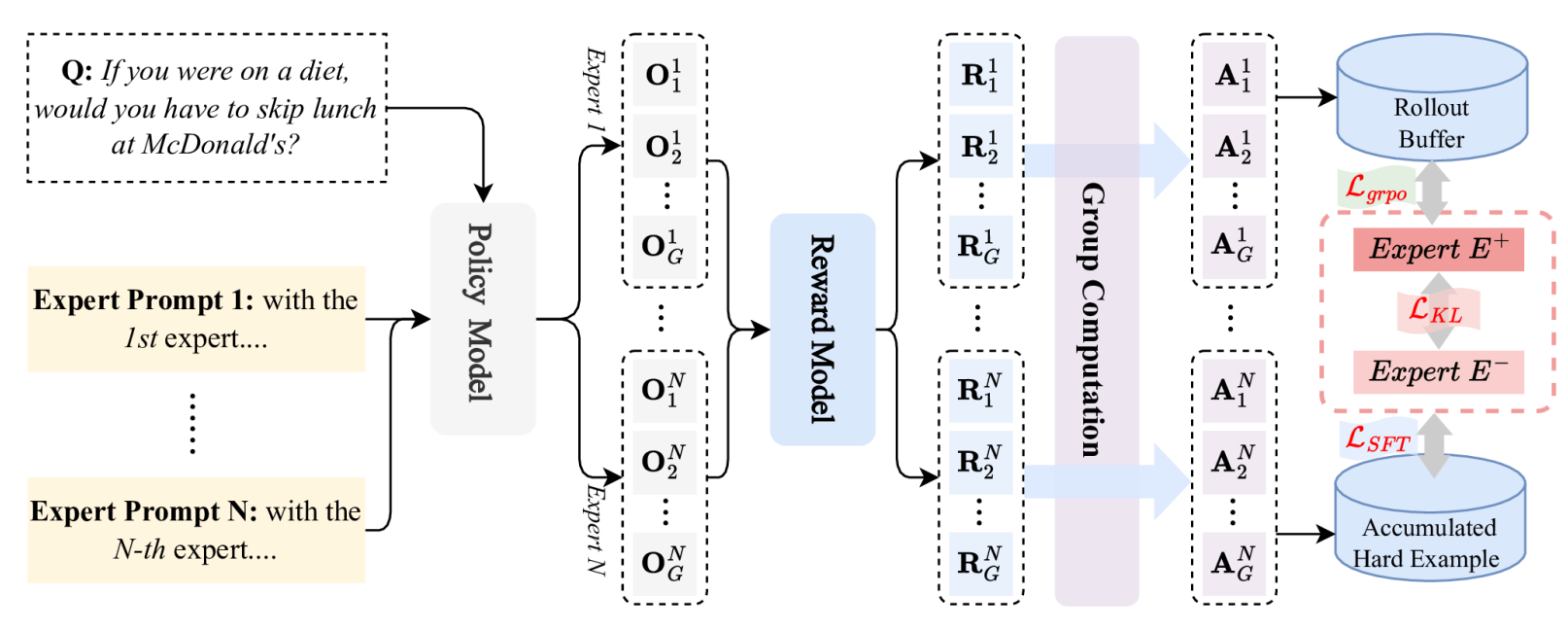
MEML-GRPO: Heterogeneous Multi-Expert Mutual Learning for RLVR Advancement
Weitao Jia *, Jinghui Lu *, Haiyang Yu *, Siqi Wang, Guozhi Tang, An-Lan Wang, Weijie Yin, Dingkang Yang, Yuxiang Nie, Bin Shan, Hao Feng, Irene Li, Kun Yang, Han Wang, Jingqun Tang, Teng Fu, Changhong Jin, Chao Feng, Xiaohui Lv, Can Huang ✉️
Recent advances demonstrate that reinforcement learning with verifiable rewards (RLVR) significantly enhances the reasoning capabilities of large language models (LLMs). However, standard RLVR faces challenges with reward sparsity, where zero rewards from consistently incorrect candidate answers provide no learning signal, particularly in challenging tasks. To address this, we propose Multi-Expert Mutual Learning GRPO (MEML-GRPO), an innovative framework that utilizes diverse expert prompts as system prompts to generate a broader range of responses, substantially increasing the likelihood of identifying correct solutions. Additionally, we introduce an inter-expert mutual learning mechanism that facilitates knowledge sharing and transfer among experts, further boosting the model’s performance through RLVR. Extensive experiments across multiple reasoning benchmarks show that MEML-GRPO delivers significant improvements, achieving an average performance gain of 4.89% with Qwen and 11.33% with Llama, effectively overcoming the core limitations of traditional RLVR methods.
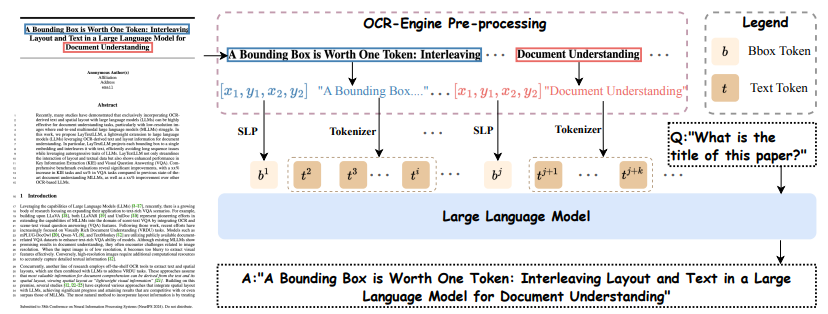
A bounding box is worth one token: Interleaving layout and text in a large language model for document understanding
Jinghui Lu *, Haiyang Yu *, Yanjie Wang, Yongjie Ye, Jingqun Tang, Ziwei Yang, Binghong Wu, Qi Liu, Hao Feng, Han Wang, Hao Liu, Can Huang ✉️
Recently, many studies have demonstrated that exclusively incorporating OCR-derived text and spatial layouts with large language models (LLMs) can be highly effective for document understanding tasks. However, existing methods that integrate spatial layouts with text have limitations, such as producing overly long text sequences or failing to fully leverage the autoregressive traits of LLMs. In this work, we introduce Interleaving Layout and Text in a Large Language Model (LayTextLLM)} for document understanding. LayTextLLM projects each bounding box to a single embedding and interleaves it with text, efficiently avoiding long sequence issues while leveraging autoregressive traits of LLMs. LayTextLLM not only streamlines the interaction of layout and textual data but also shows enhanced performance in KIE and VQA. Comprehensive benchmark evaluations reveal significant improvements of LayTextLLM, with a 15.2% increase on KIE tasks and 10.7% on VQA tasks compared to previous SOTA OCR-based LLMs.
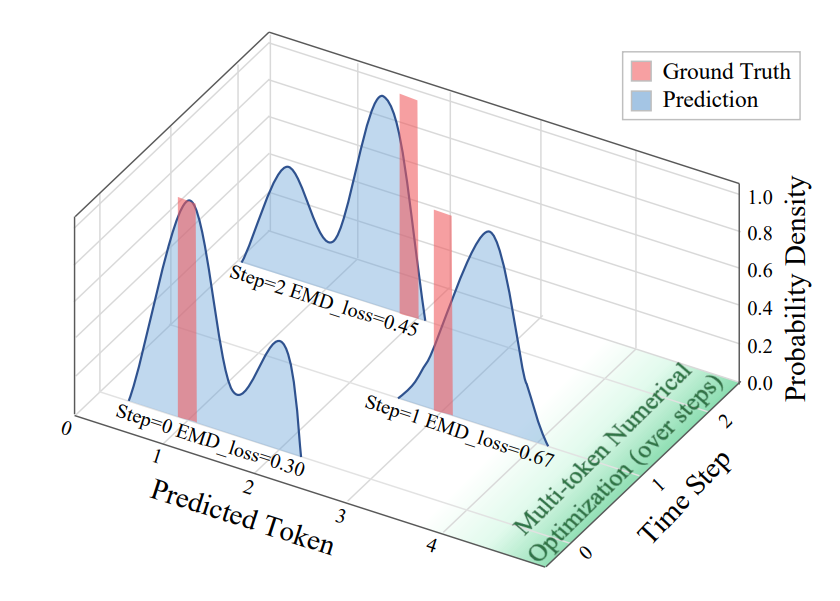
Advancing Sequential Numerical Prediction in Autoregressive Models
Xiang Fei *, Jinghui Lu *, Qi Sun *, Hao Feng ✉️, Yanjie Wang, Wei Shi, An-Lan Wang, Jingqun Tang, Can Huang ✉️
Autoregressive models have become the de facto choice for sequence generation tasks, but standard approaches treat digits as independent tokens and apply cross-entropy loss, overlooking the coherent structure of numerical sequences. This paper introduces Numerical Token Integrity Loss (NTIL) to address this gap. NTIL operates at two levels: (1) token-level, where it extends the Earth Mover’s Distance (EMD) to preserve ordinal relationships between numerical values, and (2) sequence-level, where it penalizes the overall discrepancy between the predicted and actual sequences. This dual approach improves numerical prediction and integrates effectively with LLMs/MLLMs. Extensive experiments show significant performance improvements with NTIL.
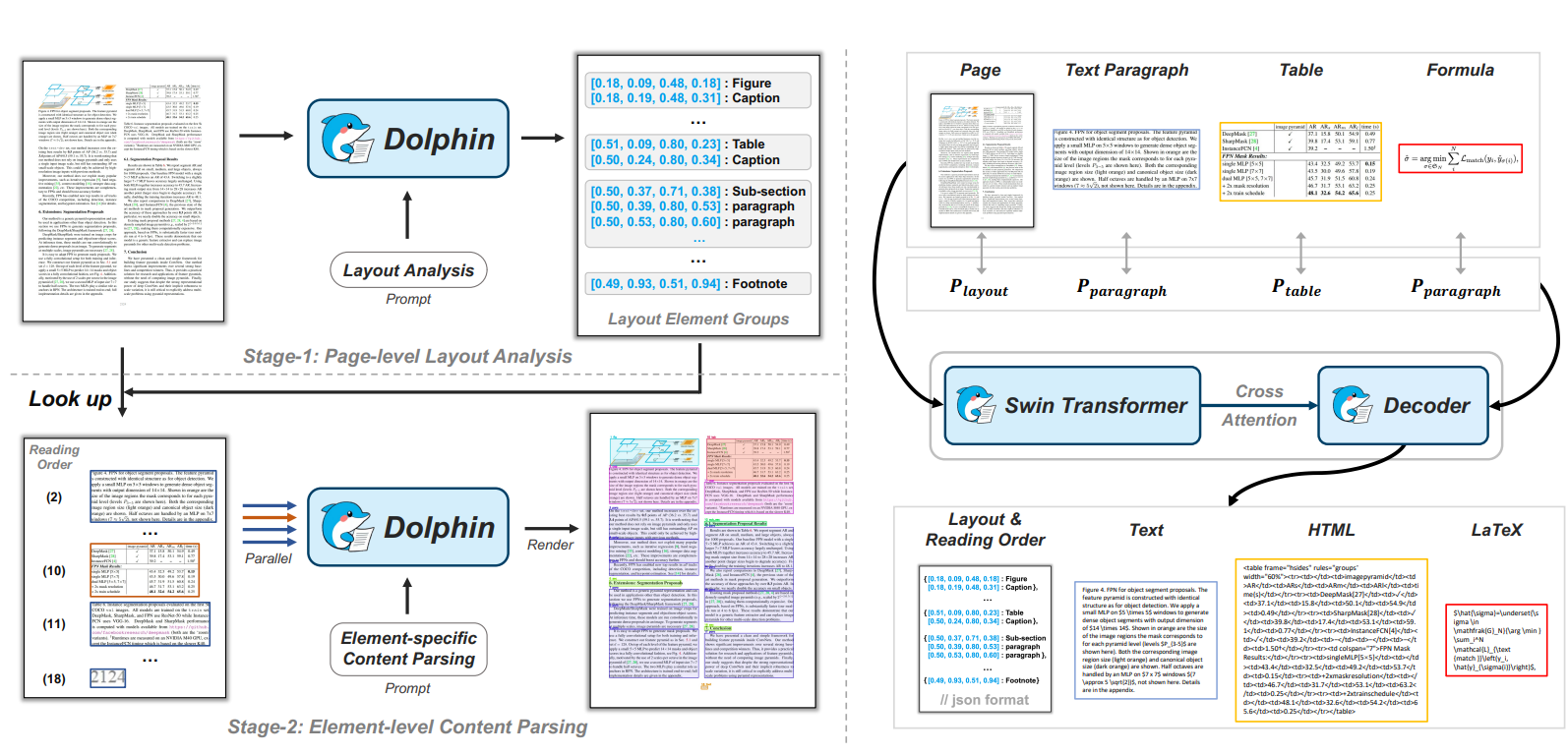
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, Jingqun Tang, Hao Liu, Can Huang ✉️
Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present Dolphin (Document Image Parsing via Heterogeneous Anchor Prompting}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism.
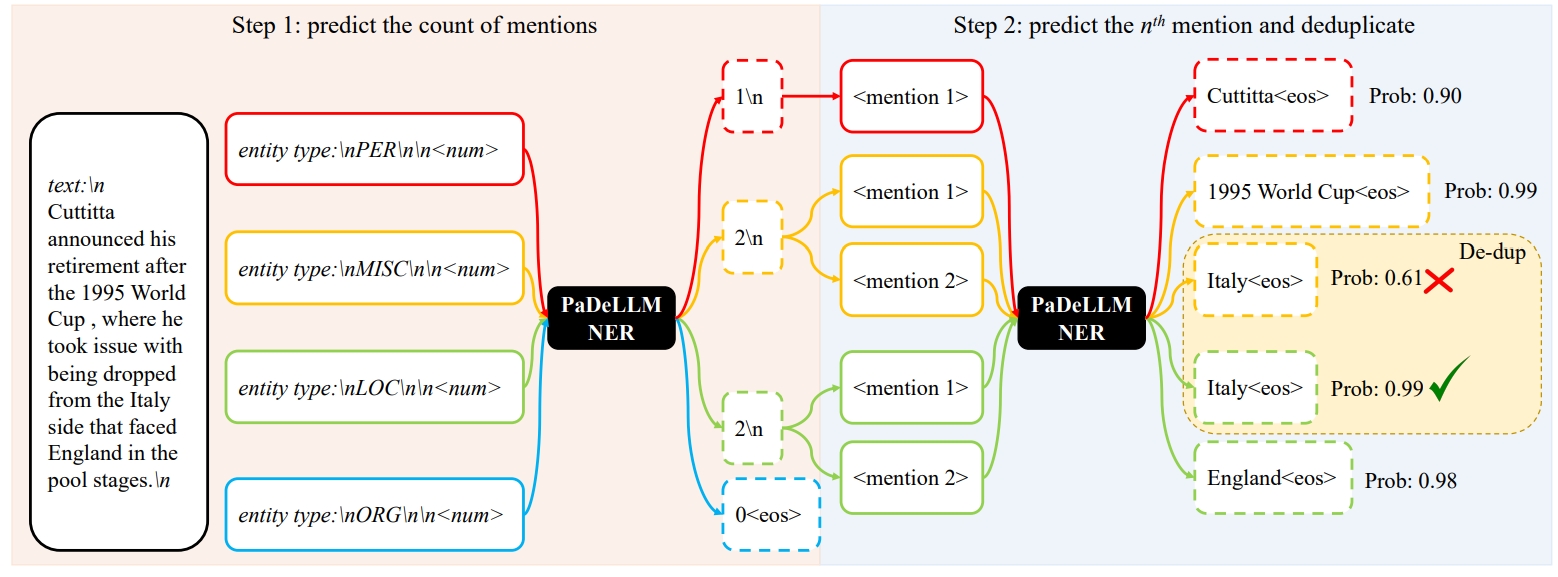
PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
Jinghui Lu *, Ziwei Yang *, Yanjie Wang *, Xuejing Liu, Brian Mac Namee, Can Huang ✉️
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
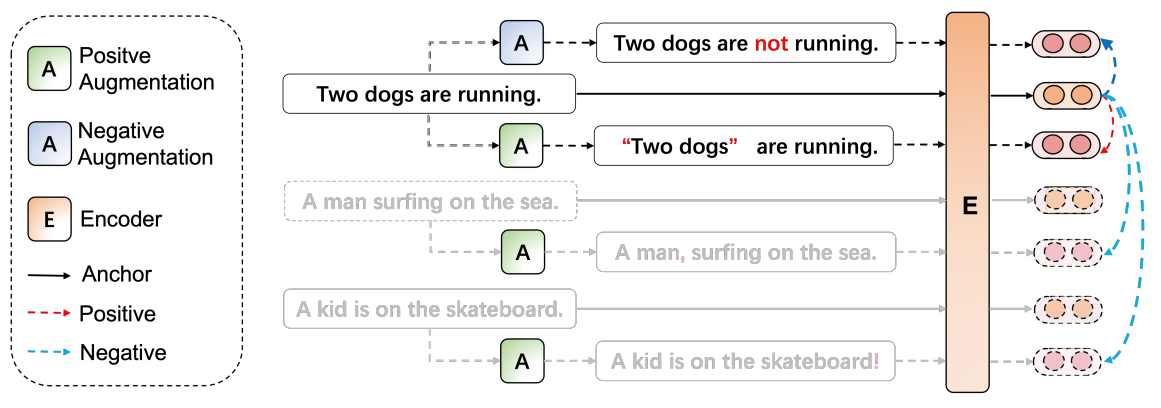
SDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Dongsheng Zhu *, Zhenyu Mao *, Jinghui Lu *, Rui Zhao, Fei Tan ✉️
Contrastive learning has recently achieved compelling performance in unsupervised sentence representation. As an essential element, data augmentation protocols, however, have not been well explored. The pioneering work SimCSE resorting to a simple dropout mechanism (viewed as continuous augmentation) surprisingly dominates discrete augmentations such as cropping, word deletion, and synonym replacement as reported. To understand the underlying rationales, we revisit existing approaches and attempt to hypothesize the desiderata of reasonable data augmentation methods: balance of semantic consistency and expression diversity. We then develop three simple yet effective discrete sentence augmentation schemes: punctuation insertion, modal verbs, and double negation. They act as minimal noises at lexical level to produce diverse forms of sentences. Furthermore, standard negation is capitalized on to generate negative samples for alleviating feature suppression involved in contrastive learning. We experimented extensively with semantic textual similarity on diverse datasets. The results support the superiority of the proposed methods consistently.
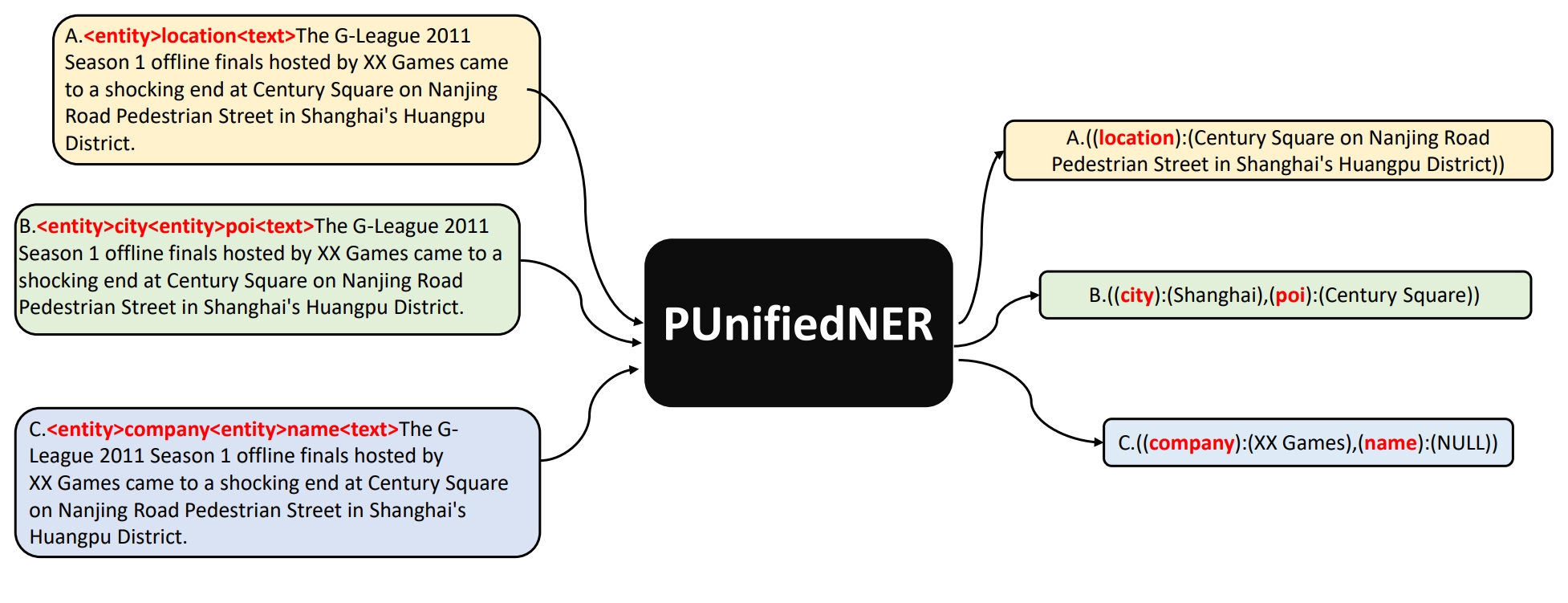
PUnifiedNER: a prompting-based unified NER system for diverse datasets
Jinghui Lu , Rui Zhao, Brian Mac Namee, Fei Tan ✉️
Much of named entity recognition (NER) research focuses on developing dataset-specific models based on data from the domain of interest, and a limited set of related entity types. This is frustrating as each new dataset requires a new model to be trained and stored. In this work, we present a “versatile” model—the Prompting-based Unified NER system (PUnifiedNER)—that works with data from different domains and can recognise up to 37 entity types simultaneously, and theoretically it could be as many as possible. By using prompt learning, PUnifiedNER is a novel approach that is able to jointly train across multiple corpora, implementing intelligent on-demand entity recognition. Experimental results show that PUnifiedNER leads to significant prediction benefits compared to dataset-specific models with impressively reduced model deployment costs. Furthermore, the performance of PUnifiedNER can achieve competitive or even better performance than state-of-the-art domain-specific methods for some datasets. We also perform comprehensive pilot and ablation studies to support in-depth analysis of each component in PUnifiedNER.
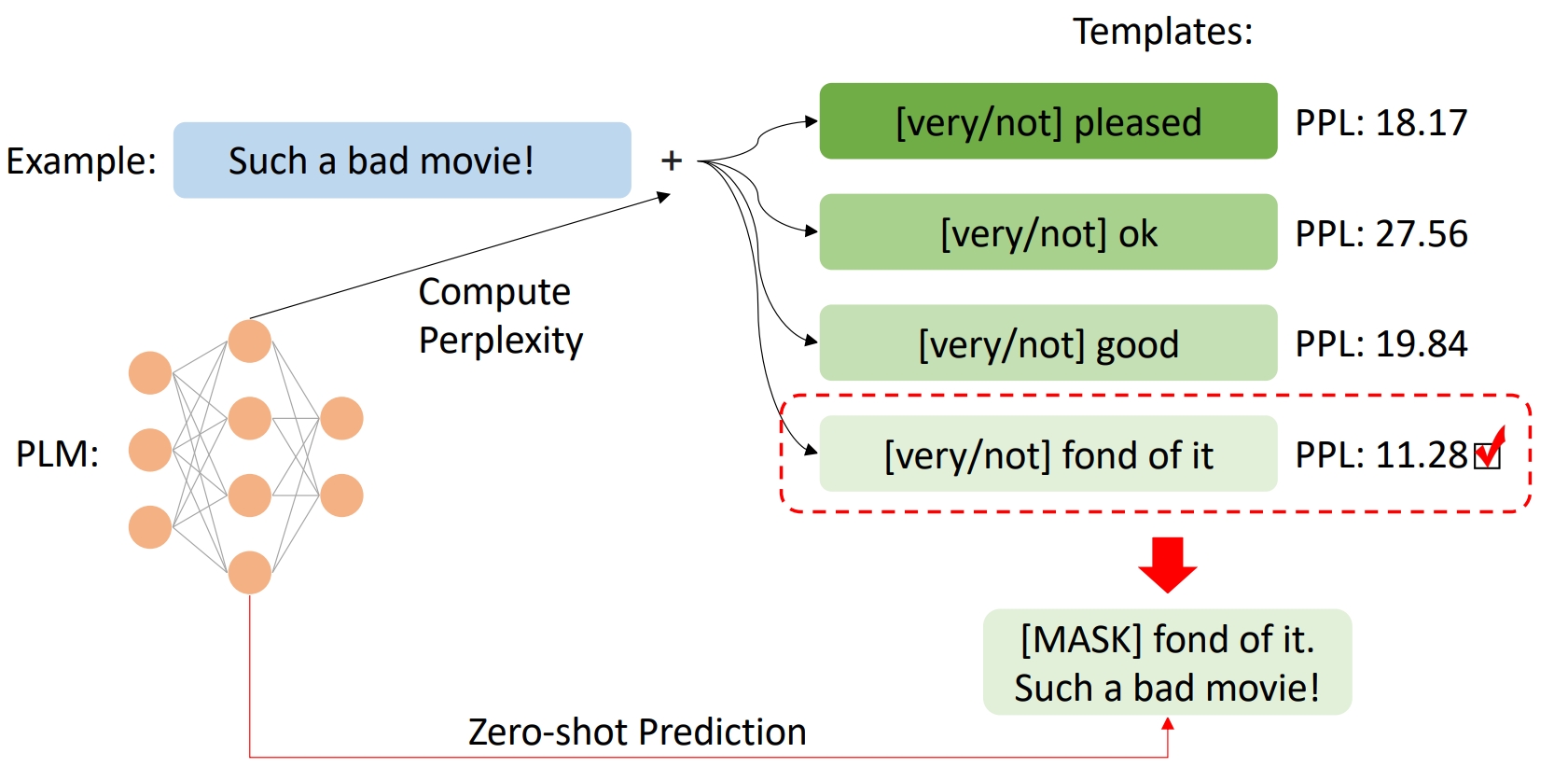
What Makes Pre-trained Language Models Better Zero-shot Learners?
Jinghui Lu , Dongsheng Zhu, Weidong Han, Rui Zhao, Brian Mac Namee, Fei Tan ✉️
Current methods for prompt learning in zero-shot scenarios widely rely on a development set with sufficient human-annotated data to select the best-performing prompt template a posteriori. This is not ideal because in a real-world zero-shot scenario of practical relevance, no labelled data is available. Thus, we propose a simple yet effective method for screening reasonable prompt templates in zero-shot text classification: Perplexity Selection (Perplection). We hypothesize that language discrepancy can be used to measure the efficacy of prompt templates, and thereby develop a substantiated perplexity-based scheme allowing for forecasting the performance of prompt templates in advance. Experiments show that our method leads to improved prediction performance in a realistic zero-shot setting, eliminating the need for any labelled examples.
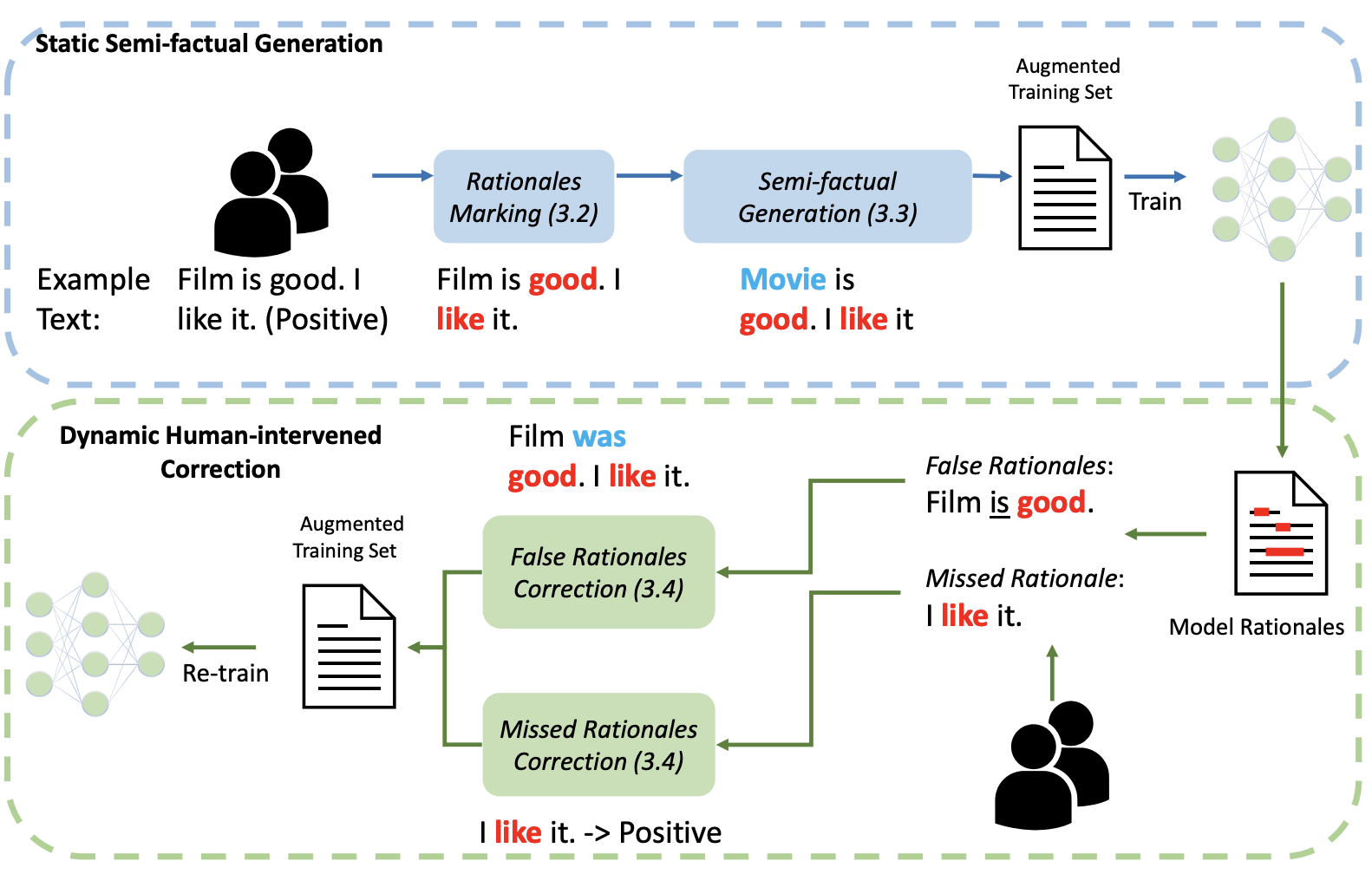
A Rationale-Centric Framework for Human-in-the-loop Machine Learning
Jinghui Lu *, Linyi Yang *, Brian Mac Namee, Yue Zhang ✉️
We present a novel rational-centric framework with human-in-the-loop – Rationales-centric Double-robustness Learning (RDL) – to boost model out-of-distribution performance in few-shot learning scenarios. By using static semi-factual generation and dynamic human-intervened correction, RDL, acting like a sensible “inductive bias”, exploits rationales (i.e. phrases that cause the prediction), human interventions and semi-factual augmentations to decouple spurious associations and bias models towards generally applicable underlying distributions, which enables fast and accurate generalisation. Experimental results show that RDL leads to significant prediction benefits on both in-distribution and out-of-distribution tests, especially for few-shot learning scenarios, compared to many state-of-the-art benchmarks.
🎖 Honors and Awards
- 2024.06, Award for High-Level Overseas Talents, Shanghai, China
- 2023.01, Outstanding Project Annual, SCG, SenseTime Group Ltd. China
- 2016.09, Walsh Fellowship Award, Ireland.
- 2015.09, Graduate Global Scholarship (<0.5\%), University College Dublin, Ireland
📖 Educations
- 2016.09 - 2021.01, Phd, University College Dublin, Ireland.
- 2015.09 - 2016.06, Master, University College Dublin, Ireland.
- 2011.09 - 2015.06, Undergraudate, Xiamen University, China.
- 2008.09 - 2011.06, Fuzhou No. 1 Middle School, China.
💬 Invited Talks
- 2023.01, ChatGPT’s past, present and future (CCB Trust, internal talk, Beijing, China)
- 2022.11, Diffusion Model and its Applications (SuzumuraLab tutorial, the Univeristy of Tokyo), Slide, Post
💻 Community Service
- 2020 - Now, serve as a review at ACL, AAAI, ICLR, NAACL, COLING, EMNLP, NeurIPS, CVPR, ICCV, ECCV and area chair for top AI conferences